
In 2022, there were projections predict that we will have exhausted the stock of low-quality language data by 2030 to 2050, high-quality language data before 2026, and vision data by 2030 to 2060. This might slow down ML progress.
However, the conclusions rely on the unrealistic assumptions that current trends in ML data usage and production will continue and that there will be no major innovations in data efficiency. Relaxing these and other assumptions would be promising future work.
Improvements in data efficiency is needed to continue to improve AI.
A more realistic model should take into account increases in data efficiency, the use of synthetic data, and other algorithmic and economic factors.
They have seen some promising early advances on data efficiency, so if lack of data becomes a larger problem in the future we might expect larger advances to follow. This is particularly true because unlabeled data has never been a constraint in the past, so there is probably a lot of low-hanging fruit in unlabeled data efficiency. In the particular case of high-quality data, there are even more possibilities, such as quantity-quality tradeoffs and learned metrics to extract high-quality data from low-quality sources.
All in all, they believe that there is about a 20% chance that the scaling (as measured in training compute) of ML models will significantly slow down by 2040 due to a lack of training data.
Transformers with retrieval mechanisms are more sample efficient. EfficientZero is a dramatic example of data efficiency but in a different domain.
In addition to increased data efficiency, there is of use of synthetic data being used to train language model,
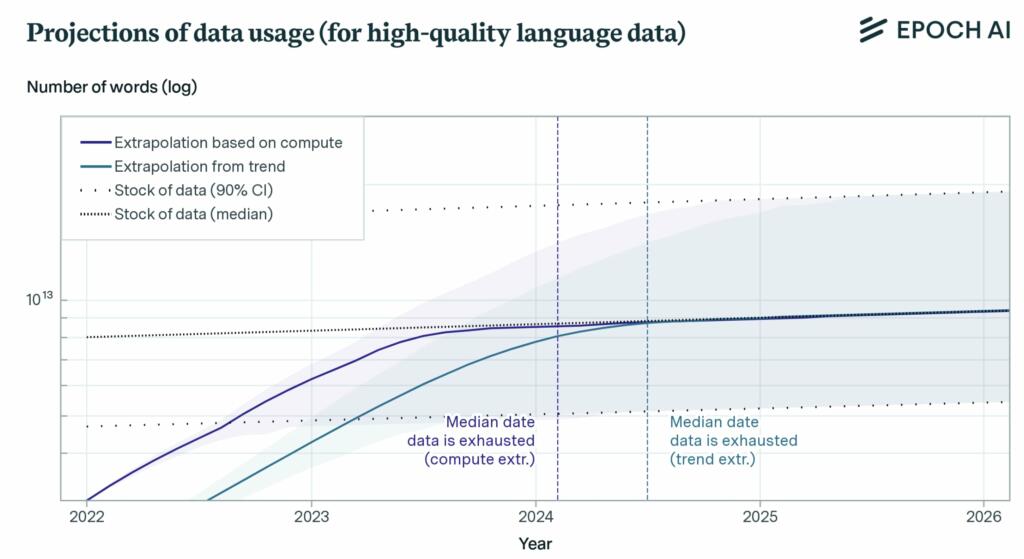
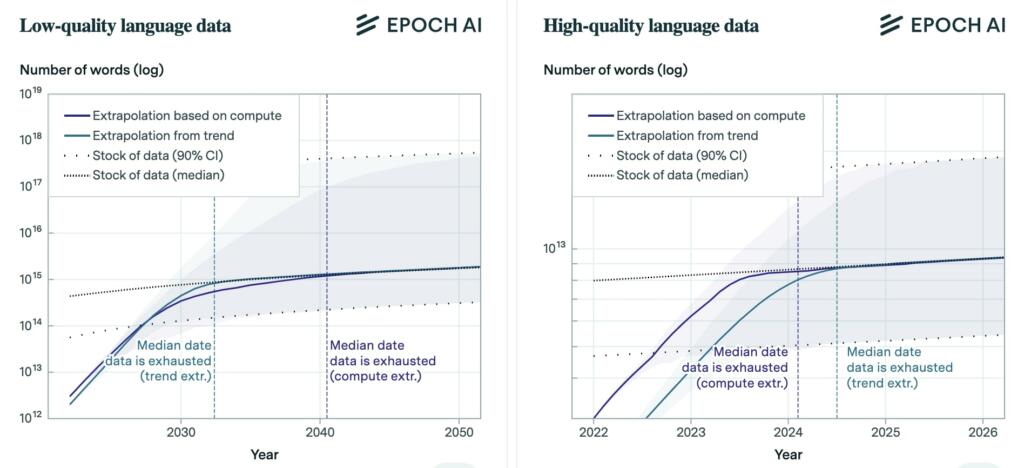
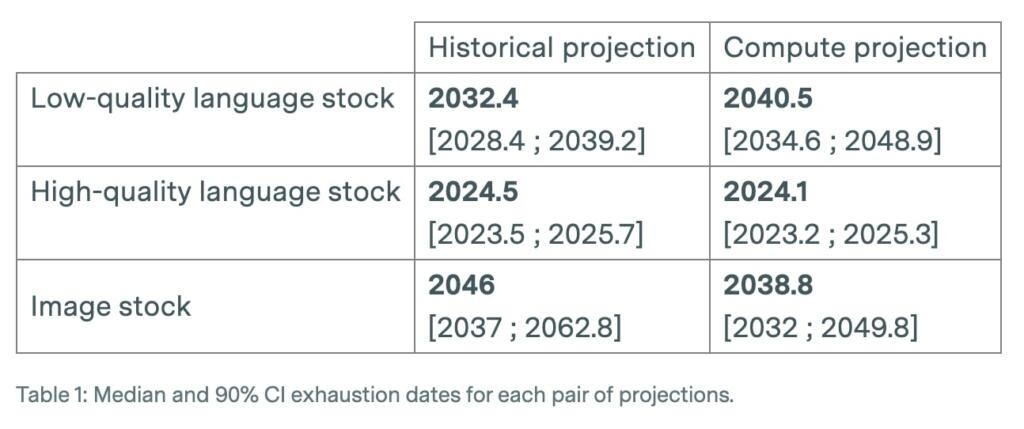
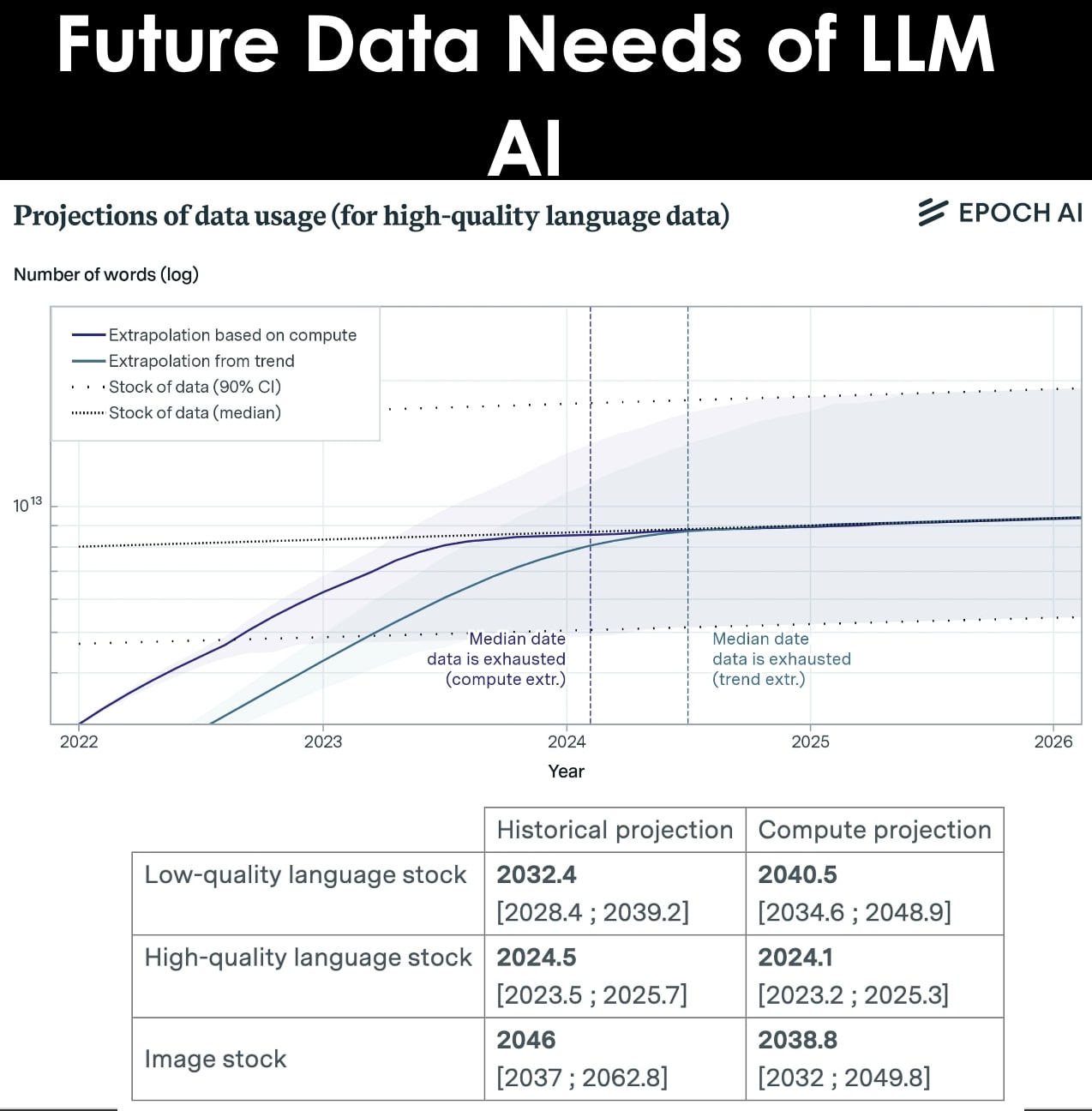
They project the growth of training datasets for vision and language models using both the historical growth rate and the compute-optimal dataset size given current scaling laws and existing compute availability estimates.
• We also project the growth in the total stock of unlabeled data, including high-quality language data .
• Language datasets have grown exponentially by more than 50% per year, and contain up to 2e12 words as of October 2022.
• The stock of language data currently grows by 7% yearly, but their model predicts a slowdown to 1% by 2100. This stock is currently between 7e13 and 7e16 words, which is 1.5 to 4.5 orders of magnitude larger than the largest datasets used today.
• Based on these trends, they will likely run out of language data between 2030 and 2050.
• However, language models are usually trained on high quality data. The stock of high-quality language data is between 4.6e12 and 1.7e13 words, which is less than one order of magnitude larger than the largest datasets.
• We are within one order of magnitude of exhausting high quality data, and this will likely happen between 2023 and 2027.
• Projecting the future growth of image datasets is less obvious than for language, because the historical trend stopped in the past four years,
• The stock of vision data currently grows by 8% yearly, but will eventually slow down to 1% by 2100. It is currently between 8.11e12 and 2.3e13 images – three to four orders of magnitude larger than the largest datasets used today .
• Projecting these trends highlights that we will likely run out of vision data between 2030 to 2070

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
The better question is – what percentage of the data available to train a new LLM in 2030 will have been AI-generated itself? It won’t be so much an issue of running out of data, but of running out of endlessly regurgitated and derivative data. We already have the issue of an obscene percentage of internet traffic just consisting of bots; can’t wait until the same thing happens to data overall.
I think the reason we need massive data to feed AI is the learning algorithms too inefficient at extracting knowledge from data, just like reactors are too inefficient at extracting energy from nuclear fuel. One solution is to rewrite data then feed it again to AI to help it extract more knowledge, just like we reprocess fuel then feed it to reactor again. I think this might be the main role of human in middle term while we waiting for more efficient algorithms
Lex Luthor: Miss Teschmacher, some people can read “War and Peace” and come away thinking it’s a simple adventure story. Others can read the ingredients on a chewing gum wrapper and unlock the secrets of the universe. – Superman (1978)
There’s no shortage of data. The genius lies in devising better ways to gather, format and analyse the data. On the flip side, we shouldn’t underestimate the sheer volume of data we humans consume and process throughout our lives either.
If we are relying entirely on larger and larger sets of recorded data to advance AI in 2030, it will truly be dead.
The current approach is partly brute force, as many GPUs as possible, and brute forcing. It is not the amount of data; true AI won’t need so much data. It would need good coding to make good decisions and good learning algorithms. Humans don’t need all the world’s GPUs and all the world’s books to learn and progress. Intelligence is not born by brute-forcing a mountain of data.
Indeed, that was my reaction: They only need this insane amount of data, millions of times what a human could absorb in a lifetime, because these programs AREN’T actually intelligent. They don’t understand anything, they’re just huge, hyperdimensional exercises in curve fitting.
An actual intelligence would be able to achieve human level results with a data set no larger than a human could process in a couple decades. A super-human AI would achieve better than human results from the same amount of data.
Instead you have driving AIs that need huge databases of actual human driving decisions to memorize, and can’t back up a trailer because there’s not enough data. Where an actual AI you could just put through a couple of weeks of driving school and it would be good to go.
This is not to say these systems can’t do anything useful. What they really underscore, though, is how little of what we do in our every day lives actually requires genuine intelligence.
Have to remember that an adult human having read a book is a model containing both that book and all of the data ingested since when that human was an infant (plus whatever knowledge is distilled into genes), so 100 thousand hours of visual, auditory, and physical qualia.
Granted, a human’s ability to learn from additional data is leaps and bounds above our best ML algorithms right now, and we clearly haven’t figured out how that works yet.
I think its going to be quite a shock that we’re going to get when we do figure out how that works and these models are able to learn and perform metacognition.
AI will start a human farm to grow data.
Agentic AI is already doing this. Using OpenAI’s GPT-4.o will provide both data and human feedback (as with Tesla FSD).
Running out of data? I doubt that’s going to happen at all soon. What we have for a very long time is not all the data we can “suck up”. It’s understanding the information in all that data that we need to know, that’s actionable, to say prevent us from being attacked. Hearing what people are saying to each other? Hell, from a technical POV, that’s easy. Understanding why someone says what they do, and what their ultimate intentions are? That can be vey hard to understand.