

Groq said that they will start operating an AI inference cluster with large business in 30 days. Groq made a presentation at the GenAI summit 2024 in San Francisco.
They are processing 30,000 inference input inference tokens and will put together about 1500 chips into an inference data center that will process 25 million inference tokens per second by the end of the year.
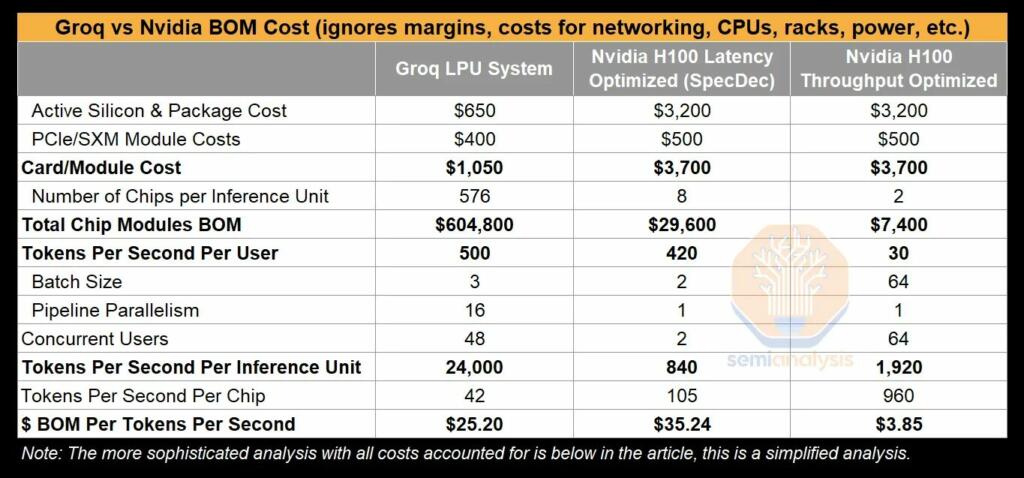
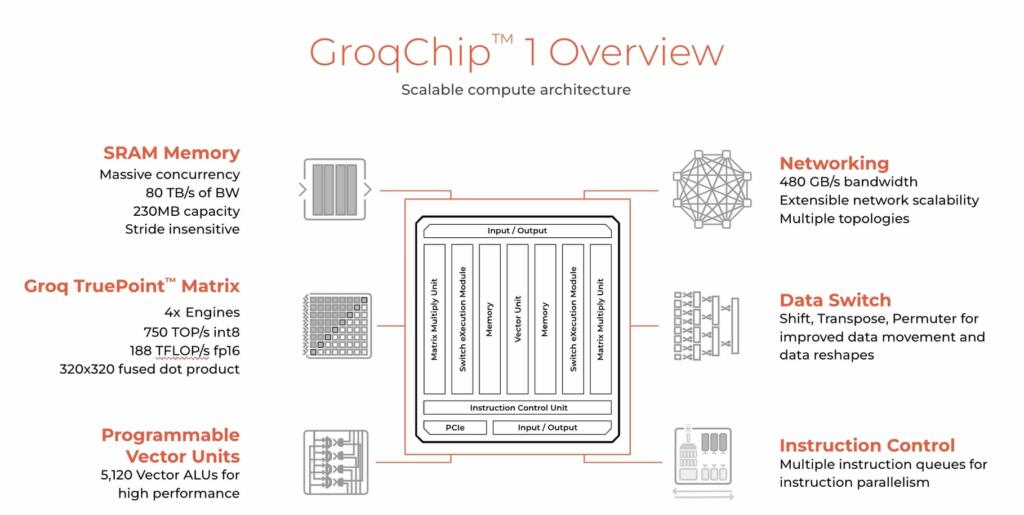
Groq uses fully synchronous SRAM memory. Nvidia uses HBM (High bandwidth stacked memory).
.
Nvidia announced that their H200 chip will process 24,000 inferences per second.
Groq says that their ASIC chip processes inferences with 3-10 times the energy efficiency of the Nvidia chips.
The AI inference chips and the AI models are making huge leaps in progress. There will soon be new stateless models.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Competition is a great thing.